Résumé de section
-

VIDÉOS COURS
https://webtv.normandie-univ.fr/channels/#architectures-pour-le-calcul
PROGRAMME
Depuis la première année, nous nous sommes attachés à appréhender les machines numériques de traitement de l'information dans une optique de compréhension des systèmes, de développemment d'application, ou d'une meilleure maîtrise du système d'exploitation. Ces approches étaient très systémiques. Cet enseignement est quant à lui dédié à l'accélération et donc l'optimisation algorithmique. Celle-ci peut s'opérer mathématiquement, en diminuant la complexité d'un algorithme, mais également à l'implémentation, en possédant une connaissance poussée de la machine d'exécution et des méthodologie d'optimisation. C'est sur ce second point que cet enseignement entend développer des compétences.
Ce cours est découpé en 2 parties. L'une ouvre l'accès à une bonne maîtrise des architectures processeurs matérielles dédiées au calcul et à l'accélération, et l'autre à la programmation parallèle sur machine dédiée.
1. Architectures matérielles pour le calcul (hugo descoubes)
- Hétérogénéité des architectures processeurs et machines de calcul : DSP, GPU, MPPA (Kalray), FPGA, ASIC (composants dédiés), SoC/SoB (hybrides), GPP et AP (généralistes), etc
- Pipelines matériels CPU : in-order classique, superscalaire, VLIW, EPIC
- Hiérarchies mémoires : caches processeurs et mémoires locales adressables. Technologies des mémoires
- Périphériques d'accélérations : DMA, fonctions algorithmiques dédiées (crypto, FFT, etc)
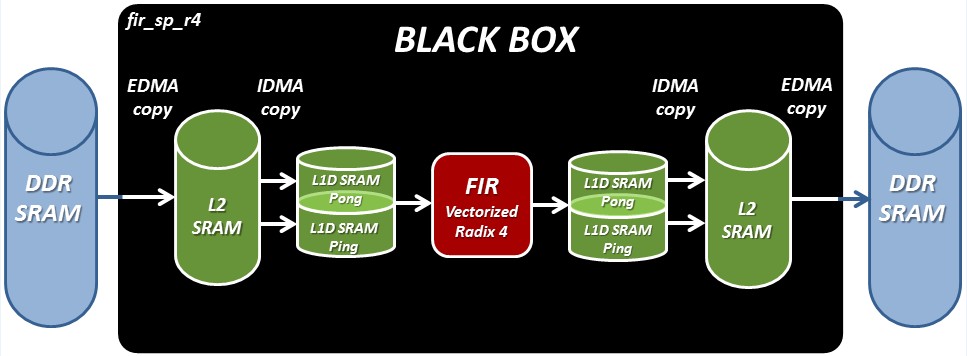
- Application de TP (DSP VLIW C6678 de Texas Instrument) : applicatif de test, validation et mesure. Optimisation d'un algorithme du TNS (application RADAR). Optimisation assembleur (Pipelining software, programmation vectorielle, VLIW, loop unrolling, etc), optimisation C (intrinsic, alignement mémoire, etc), parallélisation de copies mémoire (IDMA, EDMA, etc), Modèle mémoire (linker script, etc), etc
2. Programmation et architectures parallèles (Emmanuel Cagniot)
https://foad.ensicaen.fr/course/view.php?id=561
- Modèles d'exécution : SIMD, MIMD, etc
- Modèles mémoire : UMA, NUMA, etc
- Programmation parallèle et méthodes : Standard OpenMP, bibliothèque Intel TBB, CUDA, etc
- Application de TP (x86/x64 sous GNU\Linux) : template programming C++, découverte et application du standard OpenMP, bibliothèque Intel TBB et pipelining algorithmique